

- September 29, 2020
- Karolin Koestler, Senior Marketing Manager EMEA

In our global world, many businesses function across borders, relying upon multiple languages to get the job done. Which is why the PDF software you use should support multilingual Optical Character Recognition (OCR).
What is OCR?
(OCR) stands for Optical Character Recognition, and is a software process that enables images or printed text to be translated into machine-readable text. OCR is most commonly used when scanning paper documents to create electronic copies, but can also be performed on existing electronic documents (e.g. PDF or PDF portfolio).
When you’re performing OCR on a file—or even on a number of files in a PDF portfolio— Foxit PDF Editor software lets you select more than just one language. In fact, it can detect a wide variety of languages and can detect multiple languages within a single scanned document.
This means you can create a searchable PDF from a scanned PDF or scanned image with more than one language in it. That saves you time and effort when it comes to converting scanned documents or documents in static formats such as TIFF, JPEG and PNG into dynamic, searchable documents that your organization can use and reuse.
How to recognize text in a PDF document containing multiple languages
To create a searchable PDF from a static document that has more than one language in it, simply do the following:
- Open the Convert toolbar by one of the following:
- Choose Tools > Convert.
- Click
 in the Common Tools toolbar, and choose Convert.
in the Common Tools toolbar, and choose Convert.
- Click OCR > Current File.
- In the Select OCR Engine dialog box (shown below), do the following:
- Specify the page range to be OCRed.
- Select the language(s) used in your document.
- Choose the output type: 1) Searchable Text Image: Makes the image text searchable. 2) Editable Text: Makes the image text editable.
- Check Find All Suspects (Show all OCR results that may need to be changed.) option if you want the OCR suspects to be displayed for you to check and correct after the recognition.
- Click OK to start text recognition.
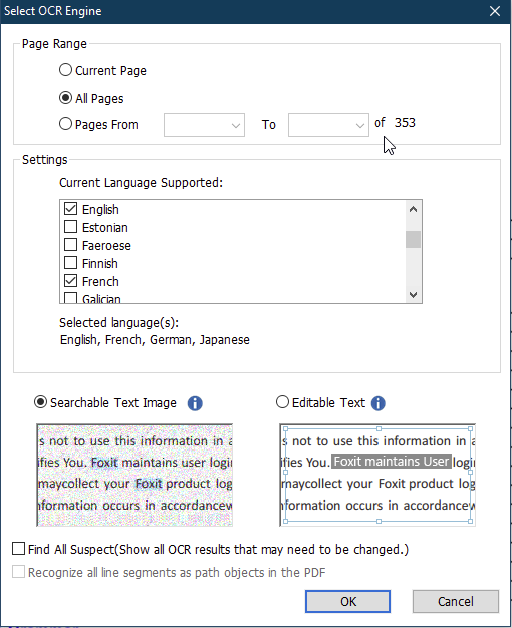
To create a searchable PDF from a document that has more than one language in it, select multiple checkboxes in the Language section of the OCR screen, and PhantomPDF will recognize words in all of the checked languages.
OCR multiple multilingual files at the same time
You’re not limited to converting multilingual documents one at a time.
To recognize text in multiple PDF files, just do this:
- Open the Convert toolbar by one of the following:
- Choose Tools > Convert.
- Click in the Common Tools toolbar, and choose Convert.
- Click OCR > Multiple Files.
- In the OCR Multiple Files dialog box, do the following:
- Click Add files, and choose Add Files, Add Folder, or Add Open Files to add a file, folder, or opened file.
- After adding the files, use the Move up or Move Down button to reorder the files, if necessary.
- Click Remove to remove the added file from the list, if necessary.
- Click Output Options to select the destination folder, and choose how to name the new file and whether to overwrite an existing one.
- Click OK.
- In the Select OCR Engine dialog box, select the language and output type, and click OK.
With Foxit PDF Editor, you can be sure you always find what you’re searching for, even if it’s in a variety of languages.
I would like to know if the latest version of Foxit PDF supports Hindi and Punjabi (Gurmukhi) as input languages to convert multi-lingual documents to machine readable format? Thanks
Hi we don’t support these documents for the moment.
Hi dear
Please if you would kindly tell me how to add the Arabic language in order to obtain the documents in the OCR method and the Arabic language.
I am tired of searching, please help me.
I have Foxit phantomPDF 7.3.6.321 pro
Hi Odai, if you have PhantomPDF 7.3 or later and want to use OCR, you need to install the Foxit OCR Add-ons. Click on the link then choose “Foxit PDF Editor for Windows”. Scroll to “OCR language” and click on the “Download” link. Choose “Arabic” from the drop-down menu, and choose your software version. Then, download. Here’s a blog post that should be helpful: https://www.foxit.com/blog/how-to-install-ocr-in-foxit-phantompdf/